Thoughts and Theory
Recent Advances in Transfer Learning for Natural Language Processing
An Overview of the Evolution of Recent Transfer Learning Techniques for Natural Language Processing (NLP)
The following is an extract from my newly released book “Transfer Learning for Natural Language Processing”. The extract summarizes some recent NLP model architectures relying on the concept of transfer learning.
Artificial intelligence (AI) has transformed modern society in a dramatic way. Tasks which were previously done by humans can now be done by machines faster, cheaper, and in some cases more effectively. Popular examples of this include computer vision applications — concerned with teaching computers how to understand images and videos — for the detection of criminals in closed-circuit television camera feeds, for instance. Other computer vision applications include detection of diseases from images of patient organs and the detection of plant species from plant leaves. Another important branch of AI, which deals particularly with the analysis and processing of human natural language data, is referred to as natural language processing (NLP). Examples of NLP applications include speech-to-text transcription and translation between various languages, among many others. AI and NLP are juxtaposed in a Venn diagram to adjacent fields in figure 1.

The most recent incarnation of the technical revolution in AI, robotics and automation, which some refer to as the Fourth Industrial Revolution, was sparked by the intersection of algorithmic advances for training large neural networks, the availability of vast amounts of data via the internet, and the ready availability of massively parallel capabilities via graphical processing units (GPUs) which were initially developed for the personal gaming market. More specifically, the recent rapid advances in the automation of tasks relying on human perception, specifically computer vision and NLP, required these strides in neural network theory and practice to happen. This enabled sophisticated representations to be learned between input data and desired output signals to handle these difficult problems.
At the same time, projections of what AI will be able to accomplish in the near future have exceeded significantly what has been achieved in practice. We are warned of an apocalyptic future that will erase most human jobs and replace us all, potentially even an existential threat to us. NLP is not excluded from this speculation naturally, and it is today one of the most active research areas within AI.
Transfer learning aims to leverage prior knowledge from different settings — be it a different task, language, or domain — to help solve a problem at hand. It is inspired by the way in which humans learn since we typically do not learn things from scratch for any given problem but rather build on prior knowledge that may be related. For instance, learning to play a musical instrument is considered easier when one already knows how to play another instrument. Obviously, the more similar the instruments, e.g. an organ versus a piano, the more useful is prior knowledge and the easier is learning the new instrument. However, even if the instruments are vastly different, such as the drum versus the piano, some prior knowledge can still be useful even if less so. In this thought experiment, it may be partly because adhering to a rhythm would be a skill common to both instruments.
Large research laboratories, such as Lawrence Livermore National Laboratories or Sandia National Laboratories, and the large internet companies, such as Google and Facebook, are able to learn very large sophisticated models by training very deep neural networks on billions of words and millions of images. For instance, Google’s NLP model BERT was pre-trained on more than 3 billion words from the English Wikipedia (2.5 billion words) and the BooksCorpus (0.8 billion words). Similarly, deep convolutional neural networks (CNNs) have been trained on more than 14 million images of the ImageNet dataset, and the learned parameters have been widely outsourced by a number of organizations. The amounts of resources required to train such models from scratch are not typically available to the average practitioner of neural networks today, such as NLP engineers working at smaller businesses, students at smaller schools, etc. Does this mean that the smaller players are locked out of being able to achieve state-of-the-art results on their problems? Thankfully, the concept of transfer learning promises to alleviate this concern if applied correctly.
Why is Transfer Learning Important?
Transfer learning enables you to adapt or transfer the knowledge acquired from one set of tasks and/or domains to a different set of tasks and/or domains. What this means is that a model trained with massive resources — including data, computing power, time, cost, etc. — once open-sourced can be fine-tuned and re-used in new settings by the wider engineering community at a fraction of the original resource requirements. This is a big step forward for the democratization of NLP and, more widely, AI. This paradigm is illustrated in figure 2, using the act of learning how to play a musical instrument as an example. It can be observed from the figure that information-sharing between the different tasks/domains can lead to a reduction in data required to achieve the same performance for the later or downstream task B.

Recent NLP transfer learning advances
Traditionally, learning has proceeded in either a fully supervised or fully unsupervised fashion for any given problem setting — a particular combination of task, domain, and language — from scratch. Semi-supervised learning was recognized as early as 1999, in the context of support vector machines (SVMs), as a way to address potentially limited labeled data availability. An initial unsupervised pre-training step on larger collections of unlabeled data made downstream supervised learning easier. Variants of this studied how to address potentially noisy, i.e. possibly incorrect, labels — an approach sometimes referred to as weakly supervised learning. However, it was often assumed that the same sampling distribution held for both the labeled and unlabeled datasets.
Transfer learning relaxes these assumptions. The need for transfer learning was arguably popularly recognized in 1995 — as the need for “Learning to Learn” at the 1995 edition of NeurIPS. NeurIPS is probably the biggest conference in machine learning. Essentially, it stipulated that intelligent machines need to possess lifelong learning capabilities, which reuse learned knowledge for new tasks. It has since been studied under a few different names, including learning to learn, knowledge transfer, inductive bias, multi-task learning, etc. In multi-task learning, an algorithm is trained to perform well on multiple tasks simultaneously, thereby uncovering features that may be more generally useful. However, it wasn’t until around 2018 that practical and scalable methods were developed to achieve it in NLP for the hardest perceptual problems.
The year 2018 saw nothing short of a revolution in the field of NLP. The understanding in the field of how to best represent collections of text as vectors evolved dramatically. Moreover, it became widely recognized that open-sourced models could be fine-tuned or transferred to different tasks, languages, and domains. At the same time, several of the big internet companies released even more and bigger NLP models for computing such representations, and they also specified well-defined procedures for fine-tuning them. All of a sudden, the ability to attain state-of-the-art results in NLP became accessible to the average practitioner, even an independent one. It was even widely referred to as NLP’s “ImageNet moment,” referencing the explosion in computer vision applications witnessed post 2012, when a GPU-trained neural network won the ImageNet computer vision competition. Just as was the case for the original ImageNet moment, for the first time a library of pre-trained models became available for a large subset of arbitrary NLP data, together with well-defined techniques for fine-tuning them to particular tasks at hand with labeled datasets of size significantly smaller than would be needed otherwise. It is the purpose of this book to describe, elucidate, evaluate, demonstrably apply, compare, and contrast the various techniques that fall into this category. We briefly overview these techniques next.
Early explorations of transfer learning for NLP focused on analogies to computer vision, where it has been used successfully for over a decade. One such model — the Semantic Inference for the Modeling of Ontologies (SIMOn) — SIMOn, employed character-level CNNs combined with bi-directional long short term memory networks (LSTMs) for structural semantic text classification. It demonstrated NLP transfer learning methods directly analogous to those that have been used in computer vision. The rich body of knowledge on transfer learning for computer vision applications motivated this approach. The features learned by this model were shown to be also useful for unsupervised learning tasks and to work well on social media language data which can be somewhat idiosyncratic and very different from the kind of language on Wikipedia and other large book-based datasets.
One notable weakness of the original formulation of word2vec was disambiguation. There was no way to distinguish between various uses of a word that may have different meanings depending on context, i.e. homographs: e.g. duck (posture) versus duck (bird), and fair (a gathering) versus fair (just). In some sense, the original word2vec formulation represents each such word by the average vector of the vectors representing each of these distinct meanings of the homograph. Embeddings from Language Models — abbreviated ELMo after the popular Sesame Street character — is an attempt to develop contextualized embeddings of words, using bidirectional LSTMs. A high-level architectural diagram of the ELMo model is shown in figure 3.

The embedding of a word in this model depends very much on its context, with the corresponding numerical representation being different for each such context. ELMo did this by being trained to predict the next word in a sequence of words, a crucial task in the world of language modeling. Huge datasets, e.g. Wikipedia and various datasets of books, are readily available for training in this framework.
Universal Language Model Fine-tuning (ULM-FiT) is a method that was proposed to fine-tune any neural-network-based language model for any particular task and was initially demonstrated in the context of text classification. A key concept behind this method is discriminative fine-tuning, where the different layers of the network are trained at different rates. The OpenAI Generative Pretrained Transformer (GPT) modified the encoder-decoder architecture of the transformer to achieve a fine-tunable language model for NLP. This model architecture is visualized in figure 4.
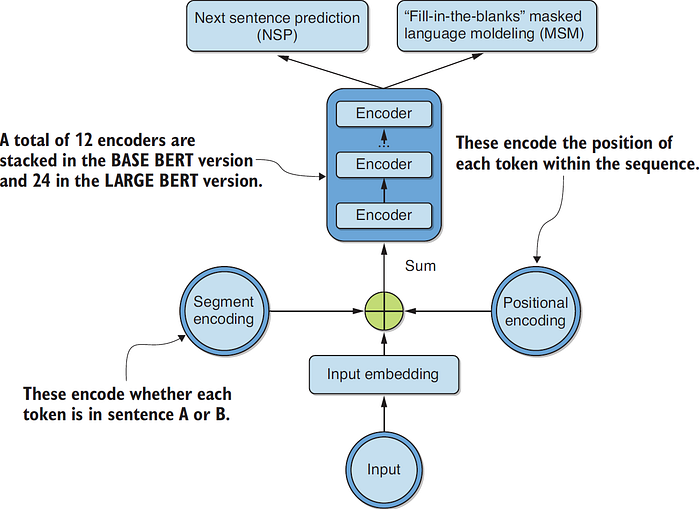
GPT discarded the encoders, retaining the decoders and their self-attention sublayers. Bidirectional Encoder Representations from Transformers (BERT) did arguably the opposite, modifying the transformer architecture by preserving the encoders and discarding the decoders, also relying on masking of words which would then need to be predicted accurately as the training metric. BERT is visualized in figure 5.

These concepts are discussed in detail in the book, in the context of hands-on practical example problems, such as spam detection, fake news classification, column type classification, chatbots, and many more.
In all of these language-model-based methods — ELMo, ULM-FiT, GPT, and BERT — it was shown that embeddings generated could be fine-tuned for specific downstream NLP tasks with relatively few labeled data points. The focus on language models was deliberate; it was hypothesized that the hypothesis set induced by them would be generally useful and the data for massive training was known to be readily available.
Since then a variety of new models have been developed building on the previously described ideas — from models such as ALBERT and DistilBERT that aim to reduce the size of BERT while achieving nearly the same performance, to models such as the LongFormer and BigBird designed to handle long documents.
The field of NLP transfer learning is currently an extremely active and exciting one, and it’s a great time to learn how to leverage it!
To learn more check out this excellent blog by Sebastian Ruder and the outstanding transformers library by Hugging Face. Also check out my repo of representative code examples on GitHub and Kaggle.
Hard copies and eBook versions of “Transfer Learning for Natural Language Processing” are available from manning.com, Amazon, Barnes & Noble, and Target .
